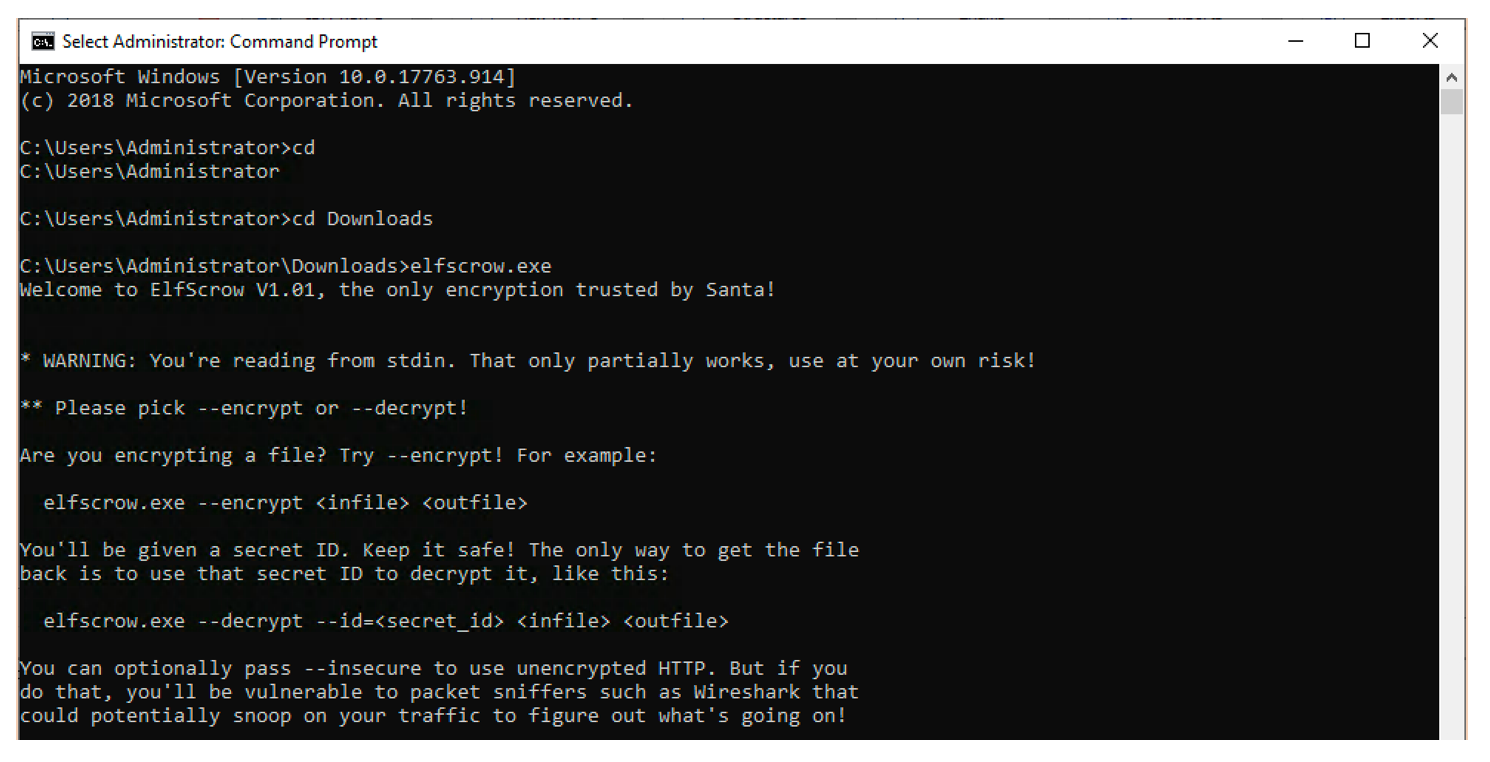
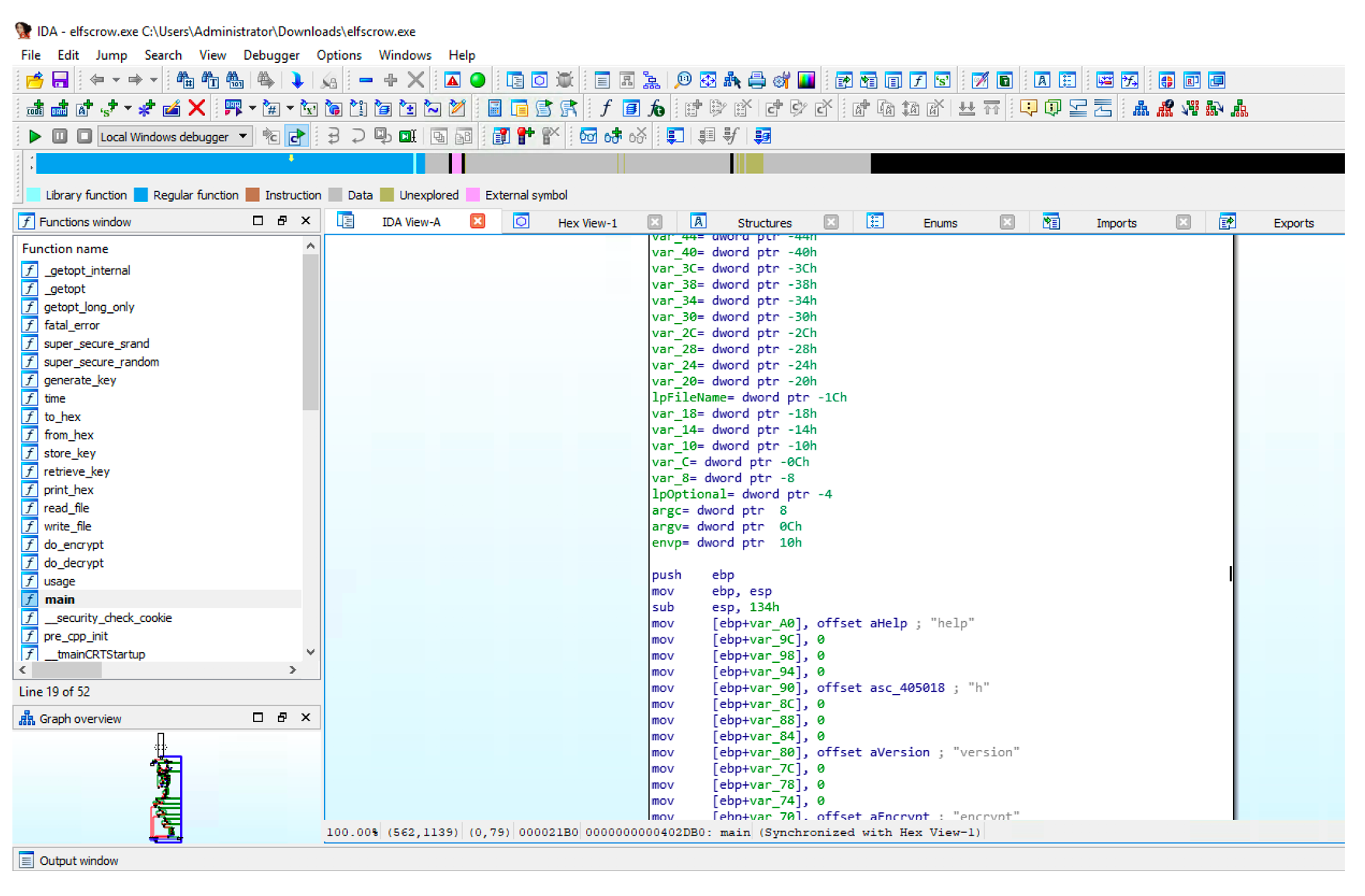
About autoencoders
As above cited an autoencoder produces (or tries to) on its output the same data it receives in its input. The first question we may want to ask is: why will we be interested in producing the same data we provide to a prediction model? well, an excellent answer of this very legitimate question could be our case, detecting anomalies by calculation the reconstruction error rate. But autoencoders have multiple other interesting applications that could be found here.
 |
| An Autoencoder Neural Network |
Training/testing data
The dataset we are going to use is retrieved from Kaggle. It contains a list of 420465 URLs with good/bad labels to mention if the concerned URL is malicious or not. We will use only the 'good' URLs to train the autoencoder. And since it will be exciting to check if our model is working we will use both good and bad URLs for testing. 80% of data will be used for training the model after keeping only the normal cases and 20% will be used for testing.
Implementation
The implementation is coded in Python using Keras for building and training the model and Panda for data manipulation.
Data preprocessing
The following are sample rows from the raw dataset:
url,label
diaryofagameaddict.com,bad
espdesign.com.au,good
iamagameaddict.com,bad
kalantzis.net,bad
slightlyoffcenter.net,good
toddscarwash.com,bad
tubemoviez.com,bad
ipl.hk,bad
crackspider.us/toolbar/install.php?pack=exe,bad
This data is not usable in it's current state, we need to enrich it by generating the following new features:
- Length: length of the URL
- Depth: the occurrence of '/' character in the URL
- Numerical count: count of numeric characters
- Words count: count of English words present in the URL
- Special chars count: count of specials characters
All the above features could be easily extracted from a raw URL except the words count . In order to extract the word count we are using an English dictionary and increasing a counter every time a word in the dictionary is contained in the URL. This is a quite heavy calculation, it took me about 26 hours to get it for the current dataset. If you have any other solution, please share it as a comment. The following lines are used to generate the new features starting from the raw dataset:
import sys
import os
import csv
LETTERS = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','w','x','y','z']
SPEC_CHARS = ['+','\"','*','#','%','&','(',')','=','?','^','-','.','!','~','_','>','<']
NUMBERS = ['0','1','2','3','4','5','6','7','8','9']
enriched_csv = open('url_enriched_data.csv','w')
enriched_csv.write('len,spec_chars,domain,depth,numericals_count,word_count,label\n')
def check_url_contains_words(url):
found_words = []
for letter in LETTERS:
dictionary = open('{}/dictionary/wb1913_{}.txt'.format(os.path.dirname(os.path.realpath(__file__)),letter),'r')
for line in dictionary.readlines():
word = line.split('</B>')[0].replace('<P><B>','').lower()
if str(word) in url.lower() and len(word)>1 and word not in found_words:
found_words.append(word)
return len(found_words)
count = 0
for row in csv.reader(open('url_data.csv','r'), delimiter = ','):
#print '-----'
print str(count)
count+=1
if 'bad' in row[1].lower():
label='1'
else:
label='0'
spec_chars=0
depth = 0
numericals_count = 0
word_count=0
url = str(l[0])
#print url
word_count=check_url_contains_words(url)
for c in str(l):
if c in SPEC_CHARS:
spec_chars+=1
if c in ['/']:
depth += 1
if c in NUMBERS:
numericals_count += 1
enriched_csv.write(str(len(l[0]))+','+str(spec_chars)+',0,'+str(depth)+','+str(numericals_count)+','+str(word_count)+','+label+'\n')
Here are some sample rows wet get after using the above code (0 is used as a label for good URLs and 1 from the bad ones):
len,spec_chars,domain,depth,numericals_count,word_count,label
41, 2, 0, 3, 0, 10, 0
31, 3, 0, 2, 0, 8 , 0
22, 2, 0, 2, 0, 11, 0
21, 1, 0, 1, 2, 5 , 1
23, 1, 0, 1, 0, 8, 1
69, 5, 0, 2, 0, 52, 0
30, 2, 0, 1, 2, 13, 1
56, 3, 0, 1, 2, 22, 1
68, 7, 0, 3, 1, 31, 1
53, 2, 0, 4, 5, 24, 0
31, 6, 0, 1, 0, 11, 0
42, 3, 0, 5, 6, 15, 0
At this point our data is ready to be fed to the autoencoder. Of course, other features like domain and whois results could be generated, may be you will have the courage to make this enhancement!
Data importation
The following lines are used to import data form the CSV we prepared in the previous step and splitting it into training and testing data.
import panda as pd
# Importing data from the CSV we created using Panda
df = pd.read_csv("enriched_url_features.csv")
frauds = df[df.label == 1]
normal = df[df.label == 0]
# Remove domain row (this row is empty)
data = df.drop(['domain'], axis=1)
# use 0.8 of the data for training and the rest for testing
X_train, X_test = train_test_split(data, test_size=0.2)
# Take only the normal (non-malicious) URLs as training data
X_train = X_train[X_train.label == 0]
X_train = X_train.drop(['label'], axis=1)
y_test = X_test['label']
X_test = X_test.drop(['label'], axis=1)
X_train = X_train.values
X_test = X_test.values
Architecture of the Autoencoder
The used autoencoder contains in total 8 layers. The first three layers are used for encoding, the middle one as 'code' layer and the last three ones are used for decoding.
input_layer = Input(shape=(input_dim, ))
encoder = Dense(encoding_dim, activation="tanh",
activity_regularizer=regularizers.l1(10e-5))(input_layer)
encoder = Dense(int(encoding_dim), activation="relu")(encoder)
encoder = Dense(int(encoding_dim-2), activation="relu")(encoder)
code = Dense(int(encoding_dim-4), activation='tanh')(encoder)
decoder = Dense(int(encoding_dim-2), activation='tanh')(code)
decoder = Dense(int(encoding_dim), activation='tanh')(encoder)
decoder = Dense(input_dim, activation='relu')(decoder)
autoencoder = Model(inputs=input_layer, outputs=decoder)
Visually speaking the above implementation looks like the following:
 |
| Visualisation of the built autoencoder |
Model training
The following lines are used to train the autoencoder. We are suing 100 epochs with the batch size set to 60. The best model will be saved in model.h5 file.
nb_epoch = 100
batch_size = 60
autoencoder.compile(optimizer='adam',
loss='mean_squared_error',
metrics=['accuracy'])
checkpointer = ModelCheckpoint(filepath="model.h5",
verbose=0,
save_best_only=True)
tensorboard = TensorBoard(log_dir='./logs',
histogram_freq=0,
write_graph=True,
write_images=True)
history = autoencoder.fit(X_train, X_train,
epochs=nb_epoch,
batch_size=batch_size,
shuffle=True,
validation_data=(X_test, X_test),
verbose=1,
callbacks=[checkpointer, tensorboard]).history
Prediction and error calculation
autoencoder = load_model('model.h5')
predictions = autoencoder.predict(X_test)
mse = np.mean(np.power(X_test - predictions, 2), axis=1)
error_df = pd.DataFrame({'reconstruction_error': mse,'true_class': y_test})
fraud_error_df = error_df[error_df['true_class'] == 0]
Finding the best threshold
In order to find the threshold that provide the best results, we are using the following loop. It keep rising the threshold until attending the wanted accuracy. In this case we are trying to attend 0.6 of accuracy and 0.5 of recall.
threshold = 0
f1 = 0
recall = 0
accuracy = 0
iterations = 10000
while (recall < 0.5 or accuracy < 0.6):
if iterations == 0:
break
print '**************************'
print threshold
threshold+=.005
y_pred = [1 if e > threshold else 0 for e in error_df.reconstruction_error.values]
conf_matrix = confusion_matrix(error_df.true_class, y_pred)
tn, fp, fn, tp = conf_matrix.ravel()
precision = 1.*tp/(tp+fp)
recall = 1.*tp/(tp+fn)
f1=(2*recall*precision)/(recall+precision)
print 'TP:'+str(tp)
print 'FP:'+str(fp)
print 'TN:'+str(tn)
print 'FN:'+str(fn)
accuracy=1.*(tp+tn)/(tp+tn+fp+fn)
print 'Accuracy:'+str(accuracy)
print 'Precision:'+str(precision)
print 'Recall:'+str(recall)
print 'F1:'+str(f1)
After several iterations, we obtained the following result:
In the following chart, the selected threshold (1.83 is this case) is represented by the red line.
This figure represents all the points with the threshold
Zooming the area above the threshold (malicious URLs)
Zooming on the area below the threshold (normal URLs)
This represents the following results: Accuracy: 60%, Precision: 22.62%, Recall: 50.42%.
Source code
Conclusion
Although we haven't got an excellent prediction results for the built model, this article showed that using autoencoders could be a good solution when it is about unlabelled datasets especially in cybersecurity contexts where early anomalies detection is a key for proactive approaches. The threshold could be adapted to the problem you are trying to solve, it should be calculated according to if recall is important for you or a good global accuracy is enough.